
Artificial intelligence (AI) at the enterprise level has moved from experimentation to executive priority. Across industries, enterprises are launching pilots, proofs of concept, and early deployments designed to improve decision-making, automate workflows, and drive operational efficiency.
Yet expectations continue to outpace results. While many enterprises can point to successful AI pilots, far fewer have translated those initial wins into sustained operational impact. In its 2026 Global CEO Survey of 4,454 chief executives across 95 countries, global consultancy PwC reported that 56% of respondents saw “neither higher revenues nor lower costs from AI”.[1]
This highlights an uncomfortable truth: the main AI challenge most organizations face today is not building AI models; it is building environments where AI can operate reliably. Scaling AI is often blocked by issues with infrastructure readiness, data accessibility, and systems of execution that were never designed for AI-driven operations.
In controlled pilot settings, AI generally performs well. In actual operational environments, complexity hinders scaling. Production systems span multiple sites, legacy platforms, proprietary equipment, and fragmented data sources. Beyond technical complexity, operational environments also involve governance structures, change management dynamics, cross-functional dependencies, and organizational readiness factors that influence how AI is adopted and sustained. What worked in isolated pilots often struggles when exposed to the realities of enterprise operations.
As a fractional Chief AI Officer advising enterprises across industries, I see this pattern repeatedly. This blog explores why AI pilots often fail to scale, identifies the recurring infrastructure and connectivity patterns behind the problem, and outlines practical considerations for leaders seeking to move from experimentation to sustained operational impact. As AI moves from experimentation to operational dependency, enterprises that solve infrastructure readiness first often widen the performance gap.
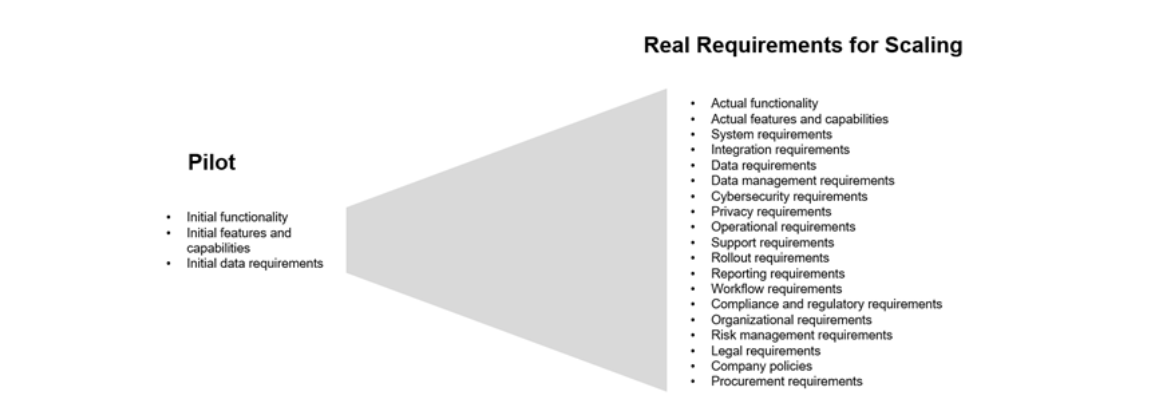
Pilot Success Doesn’t Guarantee Scaling Success
Pilots are intentionally designed to prove feasibility under controlled conditions. They are scoped narrowly, funded modestly, and optimized for speed. This is an appropriate approach to experiment and test new innovations, where the outcomes are uncertain, in an efficient and low-risk way.
But the pilot environment is not a miniature version of the operating environment. In pilots, data is often curated manually. Integrations are built as one-off connections. Workflows that appear automated may still rely on human review or intervention. These shortcuts allow teams to validate value quickly without addressing broader infrastructure constraints.
Operational environments are different. They are shaped by years of incremental system changes, legacy equipment, operational constraints, and organizational boundaries. Data is not neatly packaged for consumption. It originates from heterogeneous systems, may vary by site, and is often subject to reliability or formatting inconsistencies. Scaling requires AI to operate in this complex and challenging environment.
Industry research reinforces this reality. While many organizations experiment with advanced AI concepts, only a small fraction successfully operationalize them at scale. Research firm Forrester estimates that only 10–15% of AI projects reach sustained production use and that over 60% of pilots fail to scale beyond controlled environments. [2]
The gap is rarely due to AI limitations. In many enterprises, pilots are funded as experimentation initiatives, while the infrastructure modernization required for scaling sits outside the pilot’s scope. As a result, the connectivity, integration, and operational upgrades needed to support enterprise deployment are neither funded nor prioritized. This structural misalignment creates a predictable bottleneck between proof of concept and operational deployment.
The pilot proved the AI could work. Scaling revealed that the enterprise was not prepared to support it. This gap should serve as a wake-up call for enterprise leadership. As AI becomes embedded in operational decision-making, infrastructure weaknesses no longer represent minor inefficiencies; they become potential sources of operational and financial risk.
Four Infrastructure Barriers that Block AI at Scale
From an operational infrastructure perspective, I come across the same four things that break when going from pilot to scaling, no matter what the industry is. These are:
![]()
- Handcrafted integrations don’t scale. Early AI initiatives often rely on custom-built integrations such as one-off application programming interfaces (APIs), scripts, or point-to-point data pipelines created specifically for a pilot use case. These integrations enable speed but are rarely designed for enterprise reliability, governance, or reuse across multiple AI applications. As additional use cases emerge, organizations accumulate fragile connections that are difficult to maintain and risky to expand.
- Inability to collect data from operational assets. A significant portion of the data AI depends on originates outside traditional enterprise IT systems. For example, equipment, machinery, and specialized operational platforms on factory floors and field locations generate much of the data AI models need. However, this type of data is not always available or easily accessible. Legacy assets in industrial and manufacturing facilities were designed for a pre-connectivity environment. Data remains trapped on the asset itself or within separate proprietary operations technology (OT) networks. Others are not instrumented with the sensors needed to collect the signals AI models require. When operational data is incomplete, inconsistent, or difficult to access, AI systems operate with blind spots. Insights become partial. Models underperform. AI cannot optimize and act on what it cannot see.
- Inability to automate execution of insights generated by AI. Many AI systems successfully generate predictions, recommendations, or alerts, but have no means to reliably and autonomously trigger action. Acting on AI outputs typically requires integration with operational systems to initiate workflows, update enterprise systems, adjust operational parameters, or interact with equipment and field assets. In pilot environments, this limitation is often masked because teams manually review AI outputs and take action themselves or rely on temporary integrations built for a single use case. At enterprise scale, these one-off integrations are not sustainable. When operational systems are not consistently connected or integrated into execution workflows, AI cannot reliably influence real-world processes. The result is “insight without execution,” where AI demonstrates analytical value but fails to deliver measurable operational impact.
- Infrastructure is not managed for AI-driven operations. Scaling AI requires operational infrastructure to be managed for continuous data flow, system reachability, and automated execution across distributed environments. Enterprises need data streams that are reliable, systems that can be consistently accessed, and connectivity, security, and governance monitored globally. Some enterprise and operational infrastructure was originally designed and managed primarily for uptime and local reliability, not for continuous data exchange across sites, systems, and partners. Connectivity is often implemented in fragmented ways, visibility is limited to individual systems or locations, and data availability is not consistently monitored as an operational requirement. As a result, infrastructure may be technically “running,” yet still fail to deliver the predictable, enterprise-wide data access that AI systems require.
Scaling Is a Leadership Challenge
It is tempting to treat scaling challenges as technical and operational issues for AI or IT teams to resolve. In reality, the constraints described here span organizational, architectural, and operational boundaries. They involve capital allocation, governance structures, modernization priorities, and cross-functional coordination.
Scaling AI is not simply an extension of a pilot. It is an enterprise readiness challenge.
For enterprise executives, this shift in perspective is critical. As AI becomes embedded in decision-making and operational workflows, infrastructure gaps move from efficiency concerns to potential sources of operational and business risk. Inconsistent data, fragile integrations, and limited visibility undermine confidence in automation and slow enterprise adoption.
Organizations that address these foundational constraints early gain disproportionate advantage. Those that delay often find that competitors scale AI faster, embed execution systems deeper, and raise performance expectations in ways that are difficult to match.
What Leaders Should Do Next
To move from experimentation to enterprise impact, enterprise leaders must broaden the definition of “AI readiness” beyond model development. Treat scaling as an enterprise modernization initiative, not a pilot extension initiative.
AI scaling requires coordinated action across IT, operational technology, security, and business leadership. Position infrastructure readiness and connectivity as enterprise priorities.
These actions shift AI from isolated experimentation to sustained operational capability.
- Incorporate connectivity and data readiness into scaling decisions. When evaluating whether to advance a pilot, assess whether required data sources are reliably accessible and whether integrations can support production use. If modernization is required, include it in the roadmap and funding model.
- Design pilots with operations in mind. Structure pilots to reflect the future operational environment. Test not only model performance, but also connectivity, operational execution workflows, and governance mechanisms required for deployment.
- Build enterprise visibility into operational infrastructure. Audit and develop a baseline understanding of which assets are connected, where data originates, and where reliability or governance gaps exist. Visibility reduces surprises during scaling.
- Invest deliberately in infrastructure that supports AI-driven operations. Evaluate infrastructure investments not only for uptime, but for their ability to support continuous data exchange, enterprise monitoring, and secure automation at scale.
Closing Thoughts and Final Guidance
AI success is increasingly determined not only by how intelligent systems are, but by how well the enterprise environment supports them. Organizations that recognize this reality move beyond pilot success and begin to see measurable change in operational performance.
The question is no longer whether AI can generate insight. It is whether enterprises are building the infrastructure, connectivity, and governance required to let AI operate reliably at scale.
Those that do will move from experimentation to transformation. Those that do not may continue to celebrate pilots while waiting for impact.
References
[1] “PwC’s 29th Global CEO Survey: Leading through uncertainty in the age of AI.” PwC Insight. January 19, 2026.
[2] Pandey, T. “Forrester picks holes in IT’s AI story, say just 10-15% pilots scale.” The Economic Times, January 22, 2026.
This article was originally published on March 10, 2026 as a blog post on the Digi International website. You can find the original post here.
Thanks for reading this post. If you found this post useful, please share it with your network. Please subscribe to our newsletter and be notified of new blog articles we will be posting. You can also follow us on Twitter (@strategythings), LinkedIn or Facebook.
Related posts:
The AI Build–Buy–Partner Decision: A Strategic Framework for Executives
AI Is Everywhere. Enterprise Impact Isn’t. Here’s the Structure That Closes the Gap.